Wikitime
Wikitime was my final year project of my BSc Computer Science degree at the University of Southampton. The system took the full english text from the whole of the english wikipedia which is freely available to download and attempted to position historical events on a timeline. A demo based on the Simple English Wikipedia is available thanks to Heroku.
Historical Event Extraction

To generate a timeline of every event in history the processing system first removed all syntax and formatting from the text. Since the raw text contains wikimedia formatting which is an undocumented and messy format with no official documentation this was achieved through use of lots of regular expressions. Next the text was split into sentences with the Stanford Named Entity Recogniser which also pulls out named entities giving additional information useful for later.
At this point we could start looking at the sentences in detail. The final algorithm ran a regular expression over each sentence searching for four consecutive numbers, e.g. 1990. It would then attempt to parse the date in the location around the number looking for months and days.

This system is clearly not foolproof and was very easily confused by pretty much all of the Maths pages in Wikipedia. This issue was resolved by doing a statistical analysis of the dates extracted from the page. If a date fell outside of two standard deviations of all of the dates of the page it would be discarded. In addition any events set more than 50 years in the future (e.g. 2050) or with negative years would be discarded. This really helped to clean things up.
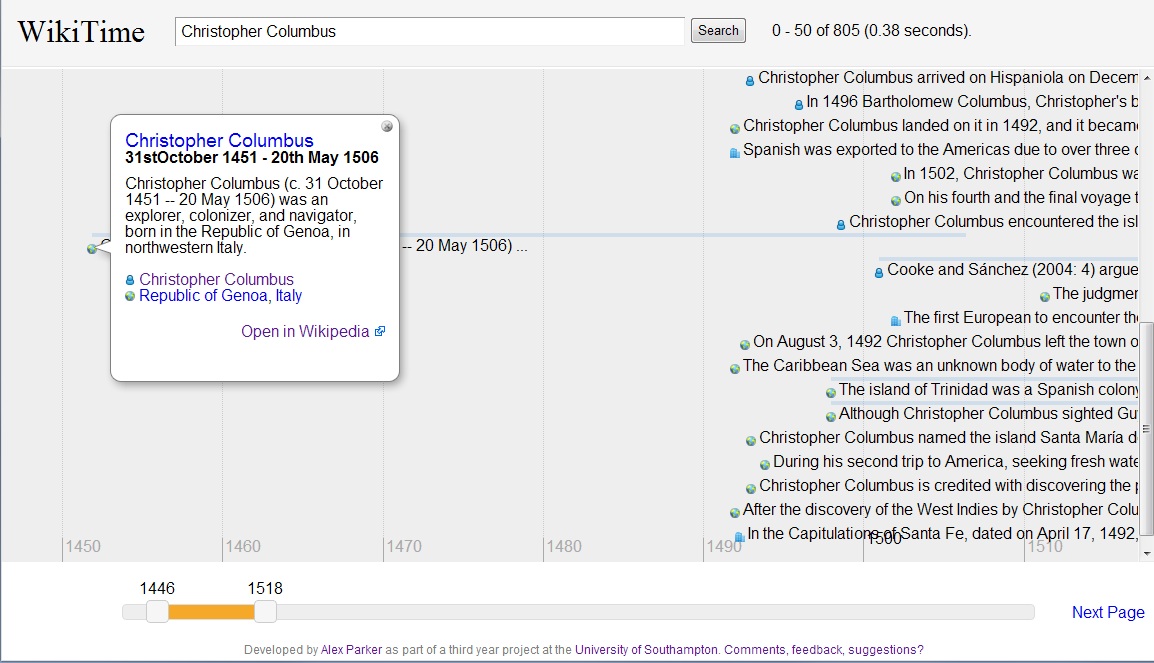
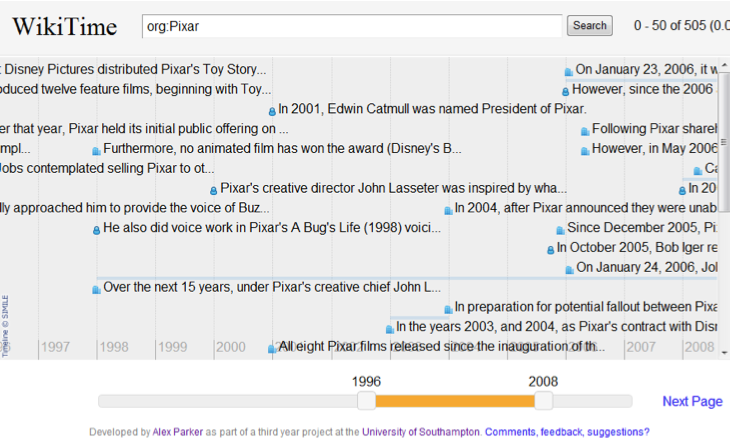
Finally all of these events were indexed into a Lucene index which could happily search over and retrieve the millions of events produced. A page rank algorithm based upon each wikipedia page ranking was applied to each event to bring the important events to the top and duplicate detection and removal was applied based upon the spot signatures algorithm.
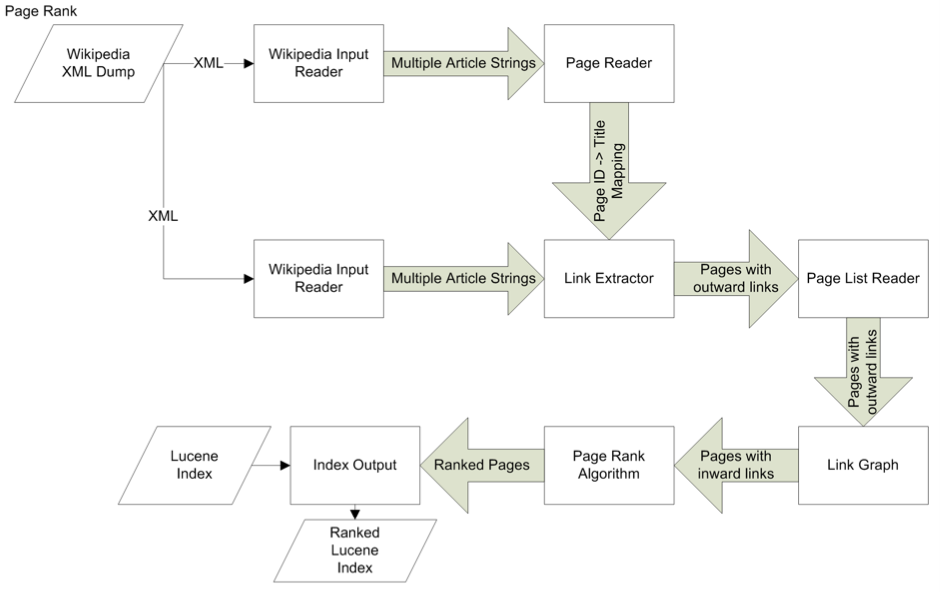
Processing the entire text of the english wikipedia was quite a challenge, since the file was around 44 GB uncompressed. To make the time to process this sane a threaded pipeline was written that splits the work over multiple threads, with queues between them. This allowed the whole wiki to be processed in around 12 hours on a reasonably powerful 12 core server my university left lying around ;)
The Website
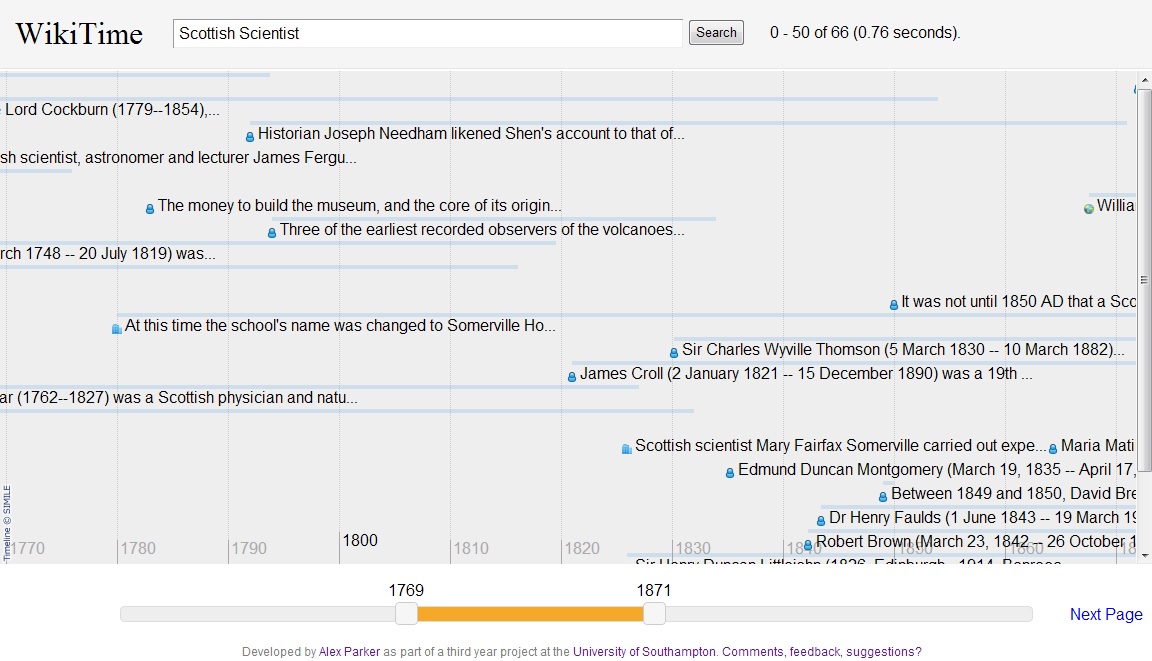
The next challenge was the website needed to display the events in a web browser in an understandable way. I ended up using the Simile Timeline Web Widget to visualise the events which I then glued to the lucene index using a bit of JQuery and Javascript. This resulted in a nice and reasonably easy to use interface.

So in conclusion it was a fun final year project for my degree which pushed my interests far beyond the graphics and game design which I had being doing in my free time up until that point. In case you missed the link above I highly recommend checking out the demo which uses the simple english wikipedia. If you are still interested in how the whole thing works, you can read my project report.